环境准备
| 节点IP | 节点规划 | 主机名 |
|---|---|---|
| 192.168.112.3 | Elasticsearch + Kibana + Logstash + Zookeeper + Kafka + Nginx | elk-node1 |
| 192.168.112.3 | Elasticsearch + Logstash + Zookeeper + Kafka | elk-node2 |
| 192.168.112.3 | Elasticsearch + Logstash + Zookeeper + Kafka + Nginx | elk-node3 |
基础环境
systemctl disable firewalld --now && setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
mv /etc/yum.repos.d/CentOS-* /tmp/
curl -o /etc/yum.repos.d/centos.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum install -y vim net-tools wget unzip
修改主机名
[root@localhost ~]# hostnamectl set-hostname elk-node1
[root@localhost ~]# bash
[root@localhost ~]# hostnamectl set-hostname elk-node2
[root@localhost ~]# bash
[root@localhost ~]# hostnamectl set-hostname elk-node3
[root@localhost ~]# bash
配置映射
[root@elk-node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.112.3 elk-node1
192.168.112.4 elk-node2
192.168.112.5 elk-node3
Elasticserach部署
安装Elasticserach
三台主机都需安装java及elasticserach
[root@elk-node1 ~]# yum install -y java-1.8.0-*
[root@elk-node1 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.0.0.rpm
[root@elk-node1 ~]# rpm -ivh elasticsearch-6.0.0.rpm
### 参数含义:i表示安装,v表示显示安装过程,h表示显示进度
启动报错
### 二进制安装
[root@elk-node1 ~]# ln -s /opt/jdk1.8.0_391/bin/java /usr/bin/java
Elasticserach配置
elk1节点配置
[root@elk-node1 ~]# cat /etc/elasticsearch/elasticsearch.yml | grep -v ^# | grep -v ^$
cluster.name: ELK
node.name: elk-node-1
node.master: true
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.112.3
http.port: 9200
discovery.zen.ping.unicast.hosts: ["elk-node1", "elk-node2","elk-node3"]
elk2节点配置
[root@elk-node2 ~]# cat /etc/elasticsearch/elasticsearch.yml | grep -v ^# | grep -v ^$
cluster.name: ELK
node.name: elk-node2
node.master: true
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.112.4
http.port: 9200
discovery.zen.ping.unicast.hosts: ["elk-node1", "elk-node2","elk-node3"]
elk3节点配置
[root@elk-node3 ~]# cat /etc/elasticsearch/elasticsearch.yml | grep -v ^# | grep -v ^$
cluster.name: ELK
node.name: elk-node3
node.master: true
node.data: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 192.168.112.5
http.port: 9200
discovery.zen.ping.unicast.hosts: ["elk-node1", "elk-node2","elk-node3"]
启动服务
[root@elk-node1 ~]# systemctl daemon-reload
[root@elk-node1 ~]# systemctl enable elasticsearch --now
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
检测进程和端口
[root@elk-node1 ~]# ps -ef | grep elasticsearch
elastic+ 12663 1 99 22:28 ? 00:00:11 /bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/var/lib/elasticsearch -Des.path.home=/usr/share/elasticsearch -Des.path.conf=/etc/elasticsearch -cp /usr/share/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch -p /var/run/elasticsearch/elasticsearch.pid --quiet
root 12720 1822 0 22:28 pts/0 00:00:00 grep --color=auto elasticsearch
[root@elk-node1 ~]# netstat -ntpl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1021/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1175/master
tcp6 0 0 192.168.112.3:9200 :::* LISTEN 12663/java
tcp6 0 0 192.168.112.3:9300 :::* LISTEN 12663/java
tcp6 0 0 :::22 :::* LISTEN 1021/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1175/master
检测集群状态
[root@elk-node1 ~]# curl 'elk-node1:9200/_cluster/health?pretty'
{
"cluster_name" : "ELK", //集群名称
"status" : "green", //集群健康状态,green为健康,yellow或者red则是集群有问题
"timed_out" : false //是否超时,
"number_of_nodes" : 3, //集群中节点数
"number_of_data_nodes" : 3, //集群中data节点数量
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Kibana部署
安装Kibana
[root@elk-node1 ~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-6.0.0-x86_64.rpm
[root@elk-node1 ~]# rpm -ivh kibana-6.0.0-x86_64.rpm
Kibana配置
添加nginx源
[root@elk-node1 ~]# vim /etc/yum.repos.d/nginx.repo
[nginx]
name = nginx repo
baseurl = https://nginx.org/packages/mainline/centos/7/$basearch/
gpgcheck = 0
enabled = 1
安装nginx
[root@elk-node1 ~]# yum install -y nginx
启动服务
[root@elk-node1 ~]# systemctl enable nginx --now
Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service.
配置nginx负载均衡
[root@elk-node1 ~]# cat /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
upstream elasticsearch {
zone elasticsearch 64K;
server elk-node1:9200;
server elk-node2:9200;
server elk-node3:9200;
}
server {
listen 80;
server_name 192.168.112.3;
location / {
proxy_pass http://elasticsearch;
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
access_log /var/log/es_access.log;
}
include /etc/nginx/conf.d/*.conf;
}
重启服务
[root@elk-node1 ~]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@elk-node1 ~]# nginx -s reload
[root@elk-node1 ~]# systemctl restart nginx
Kibana配置
[root@elk-node1 ~]# cat /etc/kibana/kibana.yml | grep -v ^#
server.port: 5601
server.host: 192.168.112.3
elasticsearch.url: "http://192.168.112.3:80"
启动服务
[root@elk-node1 ~]# systemctl enable kibana --now
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
[root@elk-node1 ~]# ps -ef | grep kibana
kibana 13384 1 32 06:02 ? 00:00:02 /usr/share/kibana/bin/../node/bin/node --no-warnings /usr/share/kibana/bin/../src/cli -c /etc/kibana/kibana.yml
root 13396 1822 0 06:03 pts/0 00:00:00 grep --color=auto kibana
浏览器访问
Zoopeeper集群部署
安装Zoopeeper
[root@elk-node1 ~]# tar -zxvf apache-zookeeper-3.8.3-bin.tar.gz -C /usr/local/
[root@elk-node1 ~]# mv /usr/local/apache-zookeeper-3.8.3-bin/ /usr/local/zookeeper
[root@elk-node1 ~]# cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
配置环境变量
[root@elk-node1 ~]# cat >> /etc/profile << EOF
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$ZOOKEEPER_HOME/bin:$PATH
EOF
[root@elk-node1 ~]# source /etc/profile
[root@elk-node1 ~]# scp /etc/profile 192.168.112.4:/etc/profile
[root@elk-node1 ~]# scp /etc/profile 192.168.112.5:/etc/profile
[root@elk-node2 ~]# source /etc/profile
[root@elk-node3 ~]# source /etc/profile
配置zoopeeper
[root@elk-node1 ~]# cat /usr/local/zookeeper/conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000 #### zookeeper 之间心跳间隔2秒
# The number of ticks that the initial
# synchronization phase can take
initLimit=10 ### LF初始通信时限
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5 ### LF同步通信时限
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/tmp/zookeeper ### zookeeper保存数据的目录
dataLogDir=/usr/local/zookeeper/logs ### zookeeper保存日志文件的目录
# the port at which the clients will connect
clientPort=2181 ### 客户端连接 zookeeper 服务器的端口
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
autopurge.purgeInterval=1
server.1=elk-node1:2888:3888
server.2=elk-node2:2888:3888
server.3=elk-node3:2888:3888
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
配置节点标识
[root@elk-node1 ~]# scp /usr/local/zookeeper/conf/zoo.cfg 192.168.112.4:/usr/local/zookeeper/conf/zoo.cfg
[root@elk-node1 ~]# scp /usr/local/zookeeper/conf/zoo.cfg 192.168.112.5:/usr/local/zookeeper/conf/zoo.cfg
[root@elk-node1 ~]# mkdir /tmp/zookeeper
[root@elk-node1 ~]# echo "1" > /tmp/zookeeper/myid
[root@elk-node2 ~]# mkdir /tmp/zookeeper
[root@elk-node2 ~]# echo "2" > /tmp/zookeeper/myid
[root@elk-node3 ~]# mkdir /tmp/zookeeper
[root@elk-node3 ~]# echo "3" > /tmp/zookeeper/myid
启动服务
三个节点都需要启动否测报错
[root@elk-node1 ~]# zkServer.sh start
/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
查看服务状态
[root@elk-node1 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
Kafka集群部署
安装Kafka
[root@elk-node1 ~]# tar -zxvf kafka_2.12-3.6.1.tgz -C /usr/local/
[root@elk-node1 ~]# mv /usr/local/kafka_2.12-3.6.1/ /usr/local/kafka
[root@elk-node1 ~]# cp /usr/local/kafka/config/server.properties{,.bak}
[root@elk-node1 ~]# scp kafka_2.12-3.6.1.tgz 192.168.112.4:/root
[root@elk-node1 ~]# scp kafka_2.12-3.6.1.tgz 192.168.112.5:/root
配置环境变量
[root@elk-node1 ~]# cat >> /etc/profile << EOF
export KAFKA_HOME=/usr/local/kafka
export PATH=$KAFKA_HOME/bin:$PATH
EOF
[root@elk-node1 ~]# source /etc/profile
[root@elk-node1 ~]# echo $KAFKA_HOME
/usr/local/kafka
[root@elk-node1 ~]# scp /etc/profile 192.168.112.4:/etc/profile
[root@elk-node1 ~]# scp /etc/profile 192.168.112.5:/etc/profile
[root@elk-node2 ~]# source /etc/profile
[root@elk-node3 ~]# source /etc/profile
配置Kafka
[root@elk-node1 ~]# grep -v "^#" /usr/local/kafka/config/server.properties.bak > /usr/local/kafka/config/server.properties
[root@elk-node1 ~]# vim /usr/local/kafka/config/server.properties
# 每一个broker在集群中的唯一表示,要求是正数
broker.id=1
# 监控的kafka端口
listenters=PLAINTEXT://192.168.112.3:9092
# broker处理消息的最大线程数,一般情况下不需要去修改
num.network.threads=3
# broker处理磁盘IO的线程数,数值应该大于你的硬盘数
num.io.threads=8
# socket的发送缓冲区
socket.send.buffer.bytes=102400
# socket的接受缓冲区
socket.receive.buffer.bytes=102400
# socket请求的最大字节数
socket.request.max.bytes=104857600
# kafka数据的存放地址,多个地址用逗号分割,多个目录分布在不同磁盘上可以提高读写性能 /tmp/kafka-log,/tmp/kafka-log2
log.dirs=/usr/local/kafka/kafka-logs
# 设置partitions的个数
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# 数据文件保留多长时间,此处为168h,粒度还可设置为分钟,或按照文件大小
log.retention.hours=168
# topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
log.retention.check.interval.ms=300000
# zookeeper集群地址
zookeeper.connect=elk-node1:2181,elk-node2:2181,elk-node3:2181
# kafka连接zookeeper的超时时间
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
[root@elk-node1 ~]# scp /usr/local/kafka/config/server.properties 192.168.112.4:/usr/local/kafka/config/server.properties
[root@elk-node1 ~]# scp /usr/local/kafka/config/server.properties 192.168.112.5:/usr/local/kafka/config/server.properties
######## 修改节点broker.id
# 每一个broker在集群中的唯一表示,要求是正数
broker.id=1
broker.id=2
broker.id=3
启动Kafka
三个节点都需要启动
### 启动
[root@elk-node1 ~]# kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
### 关闭
[root@elk-node1 ~]# kafka-server-stop.sh
ps:注: kafka节点默认需要的内存为1G,在⼯作中可能会调⼤该参数,可修改kafka-server-start.sh的配置项。找到KAFKA_HEAP_OPTS配置项,例如修改为:export KAFKA_HEAP_OPTS="-Xmx2G -Xms2G"。
测试Kafka
[root@elk-node1 ~]# jps
24099 QuorumPeerMain
48614 Jps
47384 Kafka
23258 Elasticsearch
创建Topic
`在kf1(Broker)上创建测试Tpoic:test-ken,这⾥我们指定了3个副本Broker、test-ken有2个分区`
[root@elk-node1 ~]# kafka-topics.sh --create --bootstrap-server elk-node1:9092 --replication-factor 3 --partitions 2 --topic test-ken
Created topic test-ken.
在创建Topic时不允许使⽤"_."之类的符号 选项解释:
--create:创建新的Topic
--bootstrap-server:指定要哪台Kafka服务器上创建Topic,主机加端⼝,指定的主机地址⼀ 定要和配置⽂件中的listeners⼀致
--zookeeper:指定要哪台zookeeper服务器上创建Topic,主机加端⼝,指定的主机地址⼀定要 和配置⽂件中的listeners⼀致
--replication-factor:创建Topic中的每个分区(partition)中的复制因⼦数量,即为Topic
的副本数量,建议和Broker节点数量⼀致,如果复制因⼦超出Broker节点将⽆法创建
--partitions:创建该Topic中的分区(partition)数量
--topic:指定Topic名称
查看Topic
Topic在kf1上创建后也会同步到集群中另外两个副本Broker:kf2、kf3,通过以下命令列出指定Broker的topic信息
[root@elk-node1 ~]# kafka-topics.sh --list --bootstrap-server elk-node1:9092
test-ken
[root@elk-node1 ~]# kafka-topics.sh --list --bootstrap-server elk-node2:9092 __consumer_offsets
__consumer_offsets
test-ken
查看Topic详情
[root@elk-node3 ~]# kafka-topics.sh --describe --bootstrap-server elk-node1:9092 --topic test-ken
Topic: test-ken TopicId: CMsPBF2XQySuUyr9ekEf7Q PartitionCount: 2 ReplicationFactor: 3 Configs:
Topic: test-ken Partition: 0 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Topic: test-ken Partition: 1 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
`Topic:kafka_data`: # topic名称
`PartitionCount: 2`: # 分⽚数量
`ReplicationFactor: 3`: # Topic副本数量
发送消息
向Broker(id=1)的Topic=test-ken发送消息
[root@elk-node1 ~]# kafka-console-producer.sh --broker-list elk-node1:9092 --topic test-ken
>this is test
>bye
--broker-list:指定使⽤哪台broker来⽣产消息
--topic:指定要往哪个Topic中⽣产消息
验证接收消息
### 消费者:
### 从开始位置消费(所有节点均能收到)
### elk-node1测试
[root@elk-node1 ~]# kafka-console-consumer.sh --bootstrap-server elk-node2:9092 --topic test-ken --from-beginning
this is test
bye
Processed a total of 2 messages
### elk-node2测试
[root@elk-node2 ~]# kafka-console-consumer.sh --bootstrap-server elk-node1:9092 --topic test-ken --from-beginning
this is test
bye
Processed a total of 2 messages
### 消费者组:
### ⼀个Consumer group,多个consumer进程,数量⼩于等于partition分区的数量
### test-ken只有2个分区,只能有两个消费者consumer进程去轮询消费消息
[root@elk-node1 ~]# kafka-console-consumer.sh --bootstrap-server elk-node1:9092 --topic test-ken --group testgroup_ken
删除Topic
[root@elk-node1 ~]# kafka-topics.sh --delete --bootstrap-server elk-node1:9092 --topic test-ken
查看删除信息
[root@elk-node3 ~]# kafka-topics.sh --describe --bootstrap-server elk-node1:9092 --topic test-ken
Error while executing topic command : Topic 'test-ken' does not exist as expected
[2024-01-13 15:14:10,659] ERROR java.lang.IllegalArgumentException: Topic 'test-ken' does not exist as expected
at kafka.admin.TopicCommand$.kafka$admin$TopicCommand$$ensureTopicExists(TopicCommand.scala:400)
at kafka.admin.TopicCommand$TopicService.describeTopic(TopicCommand.scala:312)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:63)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)
Zookeeper的作用
1、broker在zk中注册
kafka的每个broker(相当于⼀个节点,相当于⼀个机器)在启动时,都会在zk中注册,告诉zk其b
rokerid,在整个的集群中,broker.id/brokers/ids,当节点失效时,zk就会删除该节点,就 很⽅便的监控整个集群broker的变化,及时调整负载均衡。
WatchedEvent state:SyncConnected type:None path:null
[zk: elk-node1:2181(CONNECTED) 0] ls /brokers
[ids, seqid, topics]
[zk: elk-node1:2181(CONNECTED) 1] ls /brokers/ids
[1, 2, 3]
[zk: elk-node1:2181(CONNECTED) 2]
2、topic在zk中注册
在kafka中可以定义很多个topic,每个topic⼜被分为很多个分区。⼀般情况下,每个分区独⽴在 存在⼀个broker上,所有的这些topic和broker的对应关系都有zk进⾏维护
刚才已经删除了Topic再次创建
[root@elk-node1 ~]# kafka-topics.sh --create --bootstrap-server elk-node1:9092 --replication-factor 3 --partitions 2 --topic test-ken
Created topic test-ken.
WatchedEvent state:SyncConnected type:None path:null
[zk: elk-node1:2181(CONNECTED) 0] ls /brokers/topics/test-ken/partitions
[0, 1]
3、consumer(消费者)在zk中注册
注意:从kafka-0.9版本及以后,kafka的消费者组和offset信息就不存zookeeper了,⽽是存到
broker服务器上。 所以,如果你为某个消费者指定了⼀个消费者组名称(group.id),那么,⼀旦这个消费者启动, 这个消费者组名和它要消费的那个topic的offset信息就会被记录在broker服务器上。,但是zook
eeper其实并不适合进⾏⼤批量的读写操作,尤其是写操作。因此kafka提供了另⼀种解决⽅案:增 加__consumeroffsets topic,将offset信息写⼊这个topic
[zk: elk-node1:2181(CONNECTED) 0] ls /brokers/topics
[__consumer_offsets, test-ken]
[zk: elk-node1:2181(CONNECTED) 1] ls /brokers/topics/__consumer_offsets/partitions
[0, 1, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 3, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 4, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 5, 6, 7, 8, 9]
Beats采集⽇志部署
安装Beats
[root@elk-node1 ~]# scp filebeat-6.0.0-x86_64.rpm 192.168.112.4:/root
[root@elk-node1 ~]# scp filebeat-6.0.0-x86_64.rpm 192.168.112.5:/root
[root@elk-node1 ~]# rpm -ivh filebeat-6.0.0-x86_64.rpm
warning: filebeat-6.0.0-x86_64.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:filebeat-6.0.0-1 ################################# [100%]
Beats配置
elk-node1节点
### 编辑配置⽂件
[root@elk-node1 ~]# > /etc/filebeat/filebeat.yml
[root@elk-node1 ~]# vim vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/es_access.log ### 此处可⾃⾏改为想要监听的⽇志⽂件
output.kafka:
enabled: true
hosts: ["elk-node1:9092","elk-node2:9092","elk-node3:9092"]
topic: "es_access" ### 对应zookeeper⽣成的topic
keep_alive: 10s
elk-node2节点
[root@elk-node2 ~]# > /etc/filebeat/filebeat.yml
[root@elk-node2 ~]# vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/vmware-network.log
output.kafka:
enabled: true
hosts: ["elk-node1:9092","elk-node2:9092","elk-node3:9092"]
topic: "vmware-network"
keep_alive: 10s
elk-node3节点
[root@elk-node3 ~]# > /etc/filebeat/filebeat.yml
[root@elk-node3 ~]# vim /etc/filebeat/filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/access.log
output.kafka:
enabled: true
hosts: ["elk-node1:9092","elk-node2:9092","elk-node3:9092"]
topic: "access"
keep_alive: 10s
启动服务
[root@elk-node1 ~]# systemctl enable filebeat --now
Created symlink from /etc/systemd/system/multi-user.target.wants/filebeat.service to /usr/lib/systemd/system/filebeat.service.
[root@elk-node1 ~]# systemctl status filebeat
● filebeat.service - filebeat
Loaded: loaded (/usr/lib/systemd/system/filebeat.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2024-01-13 15:43:19 CST; 6s ago
Docs: https://www.elastic.co/guide/en/beats/filebeat/current/index.html
Main PID: 55537 (filebeat)
CGroup: /system.slice/filebeat.service
└─55537 /usr/share/filebeat/bin/filebeat -c /etc/filebeat/filebeat.yml -path.home /usr/share/filebeat -path.config /etc/filebeat -path.data /var/lib/filebeat...
Jan 13 15:43:19 elk-node1 systemd[1]: Started filebeat
Logstash部署
安装Logstash
[root@elk-node1 ~]# wget https://artifacts.elastic.co/downloads/logstash/logstash-6.0.0.rpm
[root@elk-node1 ~]# rpm -ivh logstash-6.0.0.rpm
warning: logstash-6.0.0.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:logstash-1:6.0.0-1 ################################# [100%]
Using provided startup.options file: /etc/logstash/startup.options
Successfully created system startup script for Logstash
配置Logstash
elk-node1节点
### 配置/etc/logstash/logstash.yml,修改增加如下
[root@elk-node1 ~]# grep -v '^#' /etc/logstash/logstash.yml
http.host: "192.168.112.3"
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d/*.conf
path.logs: /var/log/logstash
elk-node2节点
### 配置logstash收集es_access的⽇志
[root@elk-node2 ~]# cat /etc/logstash/conf.d/es_access.conf
# Settings file in YAML
input {
kafka {
bootstrap_servers => "elk-node1:9092,elk-node2:9092,elk-node3:9092"
group_id => "logstash"
auto_offset_reset => "earliest"
decorate_events => true
topics => ["es_access"]
type => "messages"
}
}
output {
if [type] == "messages" {
elasticsearch {
hosts => ["elk-node1:9200","elk-node2:9200","elk-node3:9200"]
index => "es_access-%{+YYYY.MM.dd}"
}
}
}
### 配置logstash收集vmware的⽇志
[root@elk-node2 ~]# cat /etc/logstash/conf.d/vmware.conf
# Settings file in YAML
input {
kafka {
bootstrap_servers => "elk-node1:9092,elk-node2:9092,elk-node3:9092"
group_id => "logstash"
auto_offset_reset => "earliest"
decorate_events => true
topics => ["vmware"]
type => "messages"
}
}
output {
if [type] == "messages" {
elasticsearch {
hosts => ["elk-node1:9200","elk-node2:9200","elk-node3:9200"]
index => "vmware-%{+YYYY.MM.dd}"
}
}
}
### 配置logstash收集nginx的⽇志
[root@elk-node2 ~]# cat /etc/logstash/conf.d/nginx.conf
# Settings file in YAML
input {
kafka {
bootstrap_servers => "elk-node1:9092,elk-node2:9092,elk-node3:9092"
group_id => "logstash"
auto_offset_reset => "earliest"
decorate_events => true
topics => ["nginx"]
type => "messages"
}
}
output {
if [type] == "messages" {
elasticsearch {
hosts => ["elk-node1:9200","elk-node2:9200","elk-node3:9200"]
index => "nginx-%{+YYYY.MM.dd}"
}
}
}
检查配置文件是否有误
[root@elk-node2 ~]# ln -s /usr/share/logstash/bin/logstash /usr/bin/
### 检查es_access
[root@elk-node2 ~]# logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/es_access.conf --config.test_and_exit
Sending Logstash's logs to /var/log/logstash which is now configured via log4j2.properties
Configuration OK
### 检查vmware
[root@elk-node2 ~]# logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/vmware.conf --config.test_and_exit
Sending Logstash's logs to /var/log/logstash which is now configured via log4j2.properties
Configuration OK
### 检查nginx
[root@elk-node2 ~]# logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/nginx.conf --config.test_and_exit
Sending Logstash's logs to /var/log/logstash which is now configured via log4j2.properties
Configuration OK
### 为ok则代表没问题
### 参数解释:
--path.settings : ⽤于指定logstash的配置⽂件所在的⽬录
-f : 指定需要被检测的配置⽂件的路径
--config.test_and_exit : 指定检测完之后就退出,不然就会直接启动了
启动Logstash
三个节点需要启动
### 检查配置⽂件没有问题后,启动Logstash服务
[root@elk-node2 ~]# systemctl enable logstash --now
Created symlink from /etc/systemd/system/multi-user.target.wants/logstash.service to /etc/systemd/system/logstash.service.
### 查看进程
[root@elk-node2 ~]# ps -ef | grep logstash
logstash 17845 1 0 17:32 ? 00:00:00 /bin/java -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+DisableExplicitGC -Djava.awt.headless=true -Dfile.encoding=UTF-8 -XX:+HeapDumpOnOutOfMemoryError -Xmx1g -Xms256m -Xss2048k -Djffi.boot.library.path=/usr/share/logstash/vendor/jruby/lib/jni -Xbootclasspath/a:/usr/share/logstash/vendor/jruby/lib/jruby.jar -classpath : -Djruby.home=/usr/share/logstash/vendor/jruby -Djruby.lib=/usr/share/logstash/vendor/jruby/lib -Djruby.script=jruby -Djruby.shell=/bin/sh org.jruby.Main /usr/share/logstash/lib/bootstrap/environment.rb logstash/runner.rb --path.settings /etc/logstash
### 查看端口
[root@elk-node2 ~]# netstat -ntpl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1151/master
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1020/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1151/master
tcp6 0 0 :::9092 :::* LISTEN 15757/java
tcp6 0 0 :::2181 :::* LISTEN 14812/java
tcp6 0 0 :::40039 :::* LISTEN 15757/java
tcp6 0 0 :::42696 :::* LISTEN 14812/java
tcp6 0 0 192.168.112.4:3888 :::* LISTEN 14812/java
tcp6 0 0 :::8080 :::* LISTEN 14812/java
tcp6 0 0 192.168.112.4:9200 :::* LISTEN 13070/java
tcp6 0 0 192.168.112.4:9300 :::* LISTEN 13070/java
tcp6 0 0 :::22 :::* LISTEN 1020/sshd
启动报错解决
[root@elk-node2 ~]# systemctl start logstash
Failed to start logstash.service: Unit not found.
[root@elk-node2 ~]# sudo /usr/share/logstash/bin/system-install /etc/logstash/startup.options systemd
which: no java in (/sbin:/bin:/usr/sbin:/usr/bin)
could not find java; set JAVA_HOME or ensure java is in PATH
[root@elk-node2 ~]# ln -s /opt/jdk1.8.0_391/bin/java /usr/bin/java
[root@elk-node2 ~]# sudo /usr/share/logstash/bin/system-install /etc/logstash/startup.options systemd
Using provided startup.options file: /etc/logstash/startup.options
Manually creating startup for specified platform: systemd
Successfully created system startup script for Logstash
如果启动服务后,有进程但是没有9600端口,是因为权限问题,之前我们以root的身份在终端启动过logstash,所以产生的相关文件的属组属主都是root,解决方法如下
[root@elk-node2 ~]# cat /var/log/logstash/logstash-plain.log | grep que
[2024-01-13T17:23:56,589][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/var/lib/logstash/queue"}
[2024-01-13T17:23:56,589][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/var/lib/logstash/dead_letter_queue"}
[root@elk-node2 ~]# ll /var/lib/logstash/
total 0
drwxr-xr-x. 2 root root 6 Jan 13 17:23 dead_letter_queue
drwxr-xr-x. 2 root root 6 Jan 13 17:23 queue
### 修改/var/lib/logstash/⽬录的所属组为logstash,并重启服务
[root@elk-node2 ~]# chown -R logstash /var/lib/logstash/
[root@elk-node2 ~]# ll /var/lib/logstash/
total 0
drwxr-xr-x. 2 logstash root 6 Jan 13 17:23 dead_letter_queue
drwxr-xr-x. 2 logstash root 6 Jan 13 17:23 queue
[root@elk-node2 ~]# systemctl restart logstash
[root@elk-node2 ~]# netstat -ntpl
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1151/master
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1020/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1151/master
tcp6 0 0 127.0.0.1:9600 :::* LISTEN 18707/java
tcp6 0 0 :::9092 :::* LISTEN 15757/java
tcp6 0 0 :::2181 :::* LISTEN 14812/java
tcp6 0 0 :::40039 :::* LISTEN 15757/java
tcp6 0 0 :::42696 :::* LISTEN 14812/java
tcp6 0 0 192.168.112.4:3888 :::* LISTEN 14812/java
tcp6 0 0 :::8080 :::* LISTEN 14812/java
tcp6 0 0 192.168.112.4:9200 :::* LISTEN 13070/java
tcp6 0 0 192.168.112.4:9300 :::* LISTEN 13070/java
tcp6 0 0 :::22 :::* LISTEN 1020/sshd
Kibana查看日志
[root@elk-node1 ~]# curl 'elk-node1:9200/_cat/indices?v'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .kibana sQtNJsqNQ3mW4Bs62m5hpQ 1 1 1 0 26.1kb 13kb
green open nginx-2024.01.13 KVTsisxoRGKs60LYwdlbVA 5 1 424 0 517.9kb 258.9kb
green open vmware-2024.01.13 S_uEeLq6TluD4fajPGAz-g 5 1 424 0 549.8kb 274.9kb
green open es_access-2024.01.13 -743RqwoQMOBhBOlkOdVWg 5 1 424 0 540.5kb 270.2kb
Web界⾯配置
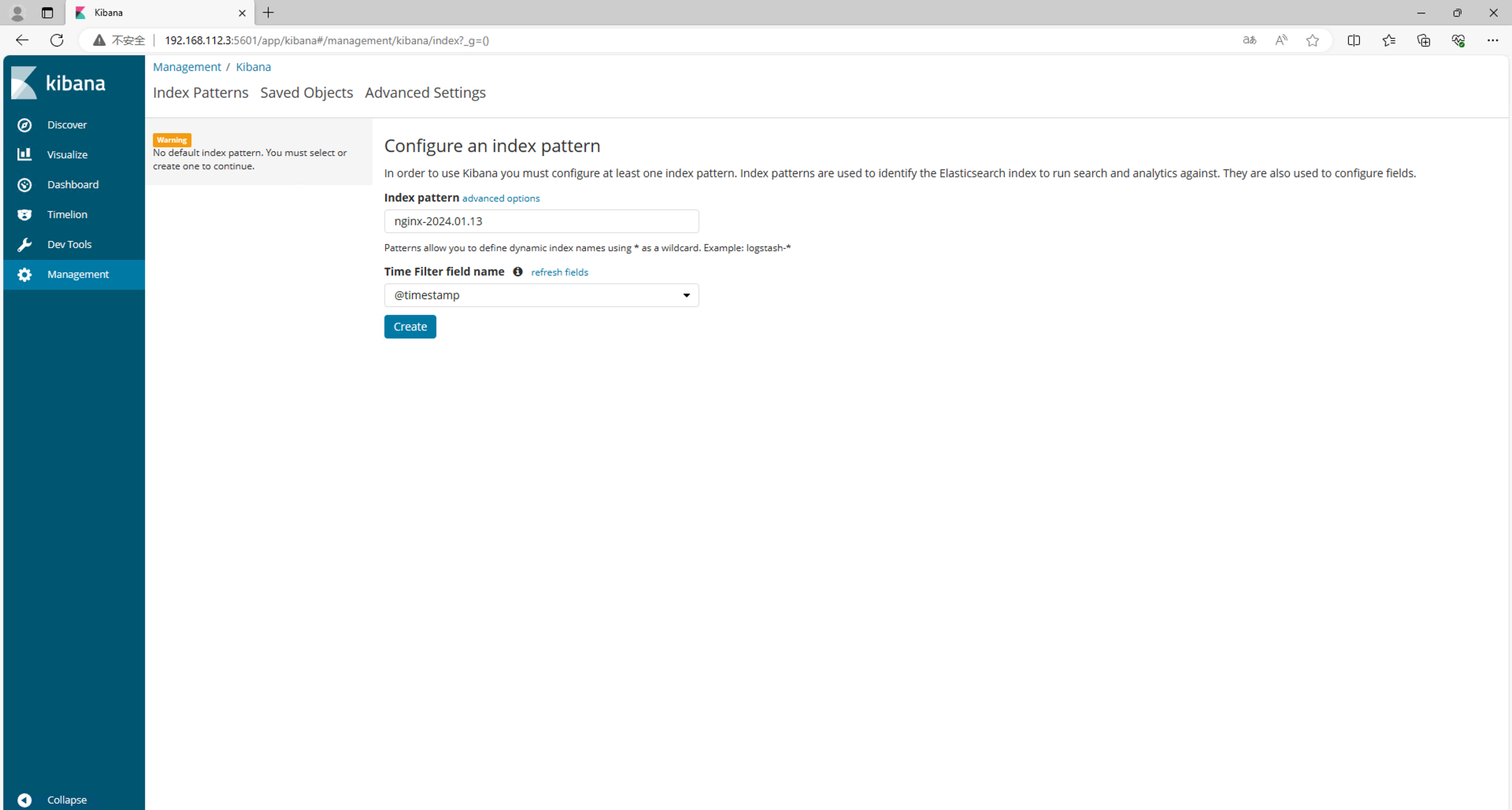
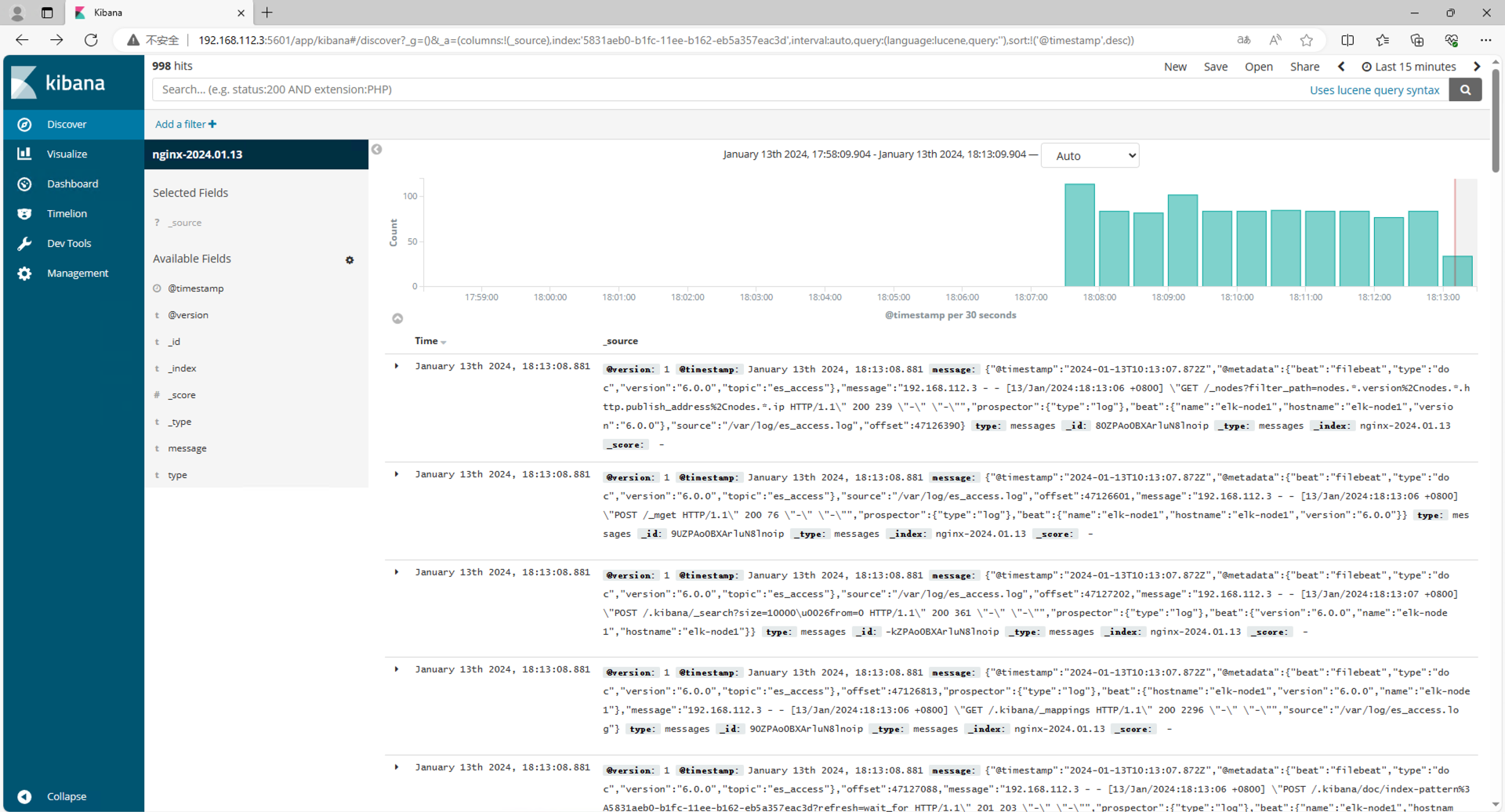
浏览器访问192.168.112.3:5601,到Kibana上配置索引
此处的 Index pattern 使用 curl 'elk-node1:9200/_cat/indices?v'获取index
⽣产部署⽅案
在⼀个⽣产集群中我们可以对这些节点进⾏划分。
建议集群中设置3台以上的节点作为master节点【
node.master: true node.data: false】
这些节点只负责成为主节点,维护整个集群的状态。
再根据数据量设置⼀批data节点【
node.master: false node.data: true】
这些节点只负责存储数据,后期提供建⽴索引和查询索引的服务,这样的话如果⽤户请求⽐较频繁,这
些节点的压⼒也会⽐较⼤
所以在集群中建议再设置⼀批client节点【
node.master: false node.data:false】
这些节点只负责处理⽤户请求,实现请求转发,负载均衡等功能。
master节点:普通服务器即可(CPU 内存 消耗⼀般)
data节点:主要消耗磁盘,内存
client节点:普通服务器即可(如果要进⾏分组聚合操作的话,建议这个节点内存也分配多⼀点)